IBM Storage Scale (formerly Spectrum Scale, formerly GPFS) is a distributed file system often found in HPC clusters, Machine Learning platforms etc. It can scale up to an unimaginable size, it can provide higher throughput than any physical drive, it allows concurrent access from many nodes in the cluster. It supports distributed locking. It has all the standard features of Unix filesystems such as quotas or ACLs. Nodes and disks can be added and removed on the fly. There's no single point of failure. It can also be accessed with S3, NFS or Hadoop compatible interface. And that's not even a full list of features.
Which also means it's not something you would run at home, not even a usual datacenter. Unless, of course, you need a playground for learning or testing. I felt quite uncomfortable running commands on a production system, that stored some petabytes of data and was used by thousands of people, without testing them first.
Creating VMs
I used Vagrant with a default provider (Virtualbox). Vagrant makes it easy to launch VMs for test environments. No need for configuration and installation, just vagrant init name-of-your-image ; vagrant up and you're done. That is, if the default configuration works for you. If not, then a simple modification to the Vagrantfile takes only a few minutes, and that's including time spent on searching the web for examples.
It's getting a bit tricky if you need to test a distributed system:
- the syntax is a little different for multiple VMs in one file,
- you should probably configure a private network,
- if you need port forwarding (eg. for SSH access), you need to use a different port for each VM.
I configured one client and three servers, sr1, sr2 and sr3. Servers both have extra hard drives in addition to the standard system drive. All machines have 2GB of RAM and 2 vCPUs (except the first server which needs more power), all connect to the same private network. All use the same operating system. Spectrum Scale supports several versions of RHEL, Ubuntu and SLES, it should work with other distributions, but no guarantees, and you'd be forced to use manual installation.
Here is my Vagrantfile. It's not the initial version, that's where I arrived after some experiments.
Vagrant.configure("2") do |config|
config.vm.define "sr1" do |sr1|
sr1.vm.box = "ubuntu/jammy64"
sr1.vm.hostname = 'sr1'
sr1.vm.provision "shell", path: "boot-tasks.sh"
sr1.vm.disk :disk, size: "1GB", name: "extra_storage1"
sr1.vm.disk :disk, size: "1GB", name: "extra_storage2"
sr1.vm.network :private_network, ip: "192.168.56.101"
#sr1.vm.network :forwarded_port, guest: 22, host: 2021, id: "ssh"
sr1.vm.provider :virtualbox do |v|
v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
v.memory = 4096
v.cpus = 4
end
end
config.vm.define "sr2" do |sr2|
sr2.vm.box = "ubuntu/jammy64"
sr2.vm.hostname = 'sr2'
sr2.vm.provision "shell", path: "boot-tasks.sh"
sr2.vm.network :private_network, ip: "192.168.56.102"
#sr2.vm.network :forwarded_port, guest: 22, host: 2022, id: "ssh"
sr2.vm.disk :disk, size: "1GB", name: "extra_storage1"
sr2.vm.disk :disk, size: "1GB", name: "extra_storage2"
sr2.vm.provider :virtualbox do |v|
v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
v.memory = 2048
v.cpus = 2
end
end
config.vm.define "sr3" do |sr3|
sr3.vm.box = "ubuntu/jammy64"
sr3.vm.hostname = 'sr3'
sr3.vm.provision "shell", path: "boot-tasks.sh"
sr3.vm.network :private_network, ip: "192.168.56.103"
#sr3.vm.network :forwarded_port, guest: 22, host: 2023, id: "ssh"
sr3.vm.disk :disk, size: "1GB", name: "extra_storage1"
sr3.vm.disk :disk, size: "1GB", name: "extra_storage2"
sr3.vm.provider :virtualbox do |v|
v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
v.memory = 2048
v.cpus = 2
end
end
config.vm.define "client" do |client|
client.vm.box = "ubuntu/jammy64"
client.vm.hostname = 'client'
client.vm.provision "shell", path: "boot-tasks.sh"
client.vm.network :private_network, ip: "192.168.56.104"
#client.vm.network :forwarded_port, guest: 22, host: 2024, id: "ssh"
client.vm.provider :virtualbox do |v|
v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
v.memory = 2048
v.cpus = 2
end
end
end
Vagrantfile references another file, boot-tasks.sh, which needs to be in the same directory. You can remove this line from Vagranfile for now, we'll use it in a few minutes. Run the first VM with vagrant up sr1. We'll use it as the installer machine. Other VMs can be started later.
Preventing installation errors
If you're running the VMs on your own computer, you might be tempted to give them less resources. Unfortunately, GPFS is a memory hog. Just the main daemon gpfsd consumes 1.2GB of RAM at startup. You need at least 2GB of RAM on all nodes, I also recommend to assign 4GB to one the nodes and use it for running GUI and installer. That means that for 3 servers and client you need at least 10GB - a bit tough if your computer only has 16GB. But if your nodes don't have enough memory, daemons will fail to start or crash, what's worse, they might not even show any meaningful error message.
I also had problems, quite ironically, with storage performance. I'm running several VMs out of one hard drive (not even SSD). Linux block layer by default timeouts if it can't finish a disk operation in 30 seconds. A reasonable value for a physical system, but if several VMs are doing write-heavy operations, it might not be enough. I'd rather wait a bit more than risk data corruption. I prepared a script time.sh and put it in the same directory as Vagrantfile. I configured Vagrant to run it automatically while rebuilding the VMs, I can also run it manually if I need to change the value.
#!/bin/bash
TIMEOUT=600
echo "Increasing disk timeout"
for f in /sys/block/sd?/device/timeout; do
echo $TIMEOUT >"$f"
done
Getting Storage Scale
Storage Scale Developer Edition is available for free, but you need to register for an IBM account and accept countless license agreements. You'll get a 1.7G zip file. Put it in the directory where you have your Vagrantfile, it will be available for VMs under /vagrant. Connect to the first server with vagrant ssh sr1. Unzip and add executable bit to the installer: chmod a+x Storage_Scale_Developer-5.1.9.0-x86_64-Linux-install and run it with root privileges: sudo ./Storage_Scale_Developer-5.1.9.0-x86_64-Linux-install.
It will list a few installation options. First one is:
To install a cluster or deploy protocols with the IBM Storage Scale Installation Toolkit:
/usr/lpp/mmfs/5.1.9.0/ansible-toolkit/spectrumscale -h
Ansible? Now you've got my attention! Last time I created GPFS testbed I installed the packages manually, but I like this option more. Let's read the documentation for the IBM Storage Scale Installation Toolkit.
The guide lists some requirements:
- obviously, we need Ansible on the machine that will start the installation:
sudo apt install ansible - we need to resolve hostnames of all nodes to IPs, either a local DNS or /etc/hosts,
- installer needs to be run as root,
- we need password-less SSH (as root! abomination!),
- we need to install make, C, and C++ compiler - on all nodes, including the client
Configuring VMs
Connect to the first server with vagrant ssh sr1. Edit /etc/hosts by adding these lines:
192.168.56.101 sr1
192.168.56.102 sr2
192.168.56.103 sr3
192.168.56.104 client
Copy the file to /vagrant. Then, generate a password-less keypair. Now, we're going to do something against the normal security rules: share the same keypair. It's fine for a temporary test environment only available on the home LAN. Copy both key files to /vagrant.
ssh-keygen
cp /etc/hosts /vagrant
cp ~vagrant/.ssh/id_rsa* /vagrant
Next, we'll add a script to so Vagrant will automatically configure all VMs. It will set the ssh keys, install required packages, and remove unattended-upgrades (this deamon has a habit of getting in the way of package installation). In the same directory where you placed Vagrantfile, add file boot-tasks.sh with the following contents:
#!/bin/sh
mkdir -p ~vagrant/.ssh
cd ~vagrant/.ssh
cp /vagrant/hosts /etc
cp /vagrant/id_rsa* .
cat id_rsa.pub >> authorized_keys
chown -R vagrant:vagrant ~vagrant/.ssh
cd /root/.ssh
cp ~vagrant/.ssh/* .
chown root:root *
apt -y remove unattended-upgrades
apt update
apt -y install g++ make
. /vagrant/time.sh
Restart machines with vagrant reload. Then try to ssh from root@sr1 to all VMs, including sr1. It should work.
Installing Storage Scale
First thing is to prepare the installer node. All commands below require root privileges:
cd /usr/lpp/mmfs/5.1.9.0/ansible-toolkit
./spectrumscale setup -s 192.168.56.101
First server will have a GUI and an admin role (-a -g). All servers will have a manager role, NSD role and will form quorum (-m -n -q) . Client is a node without any role (no extra arguments).
./spectrumscale node add sr1 -m -q -n -a -g
./spectrumscale node add sr2 -m -q -n
./spectrumscale node add sr3 -m -q -n
./spectrumscale node add client
./spectrumscale node list
NSD means Network Shared Disk. There are several possible cluster topologies for Storage Scale, many of them require some kind of shared storage. We're going to use the simplest form, where each NSD node will use its local disks. Let's define the disks now. And at the same time, define the filesystem that uses all these disks.
./spectrumscale nsd add -p sr1 /dev/sdc /dev/sdd -fs filesystem1
./spectrumscale nsd add -p sr2 /dev/sdc /dev/sdd -fs filesystem1
./spectrumscale nsd add -p sr3 /dev/sdc /dev/sdd -fs filesystem1
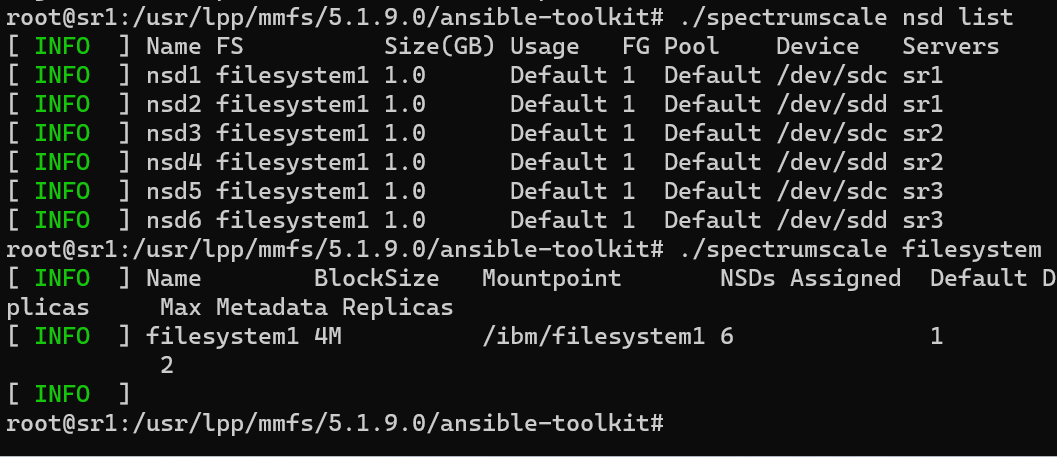
Now, check the filesystem configuration:
./spectrumscale nsd list
./spectrumscale filesystem list
Last thing to configure. By default, Spectrum Scale will send information to IBM, but this function is not configured. We need to either provide information about the customer, country etc. or simply turn it off with ./spectrumscale callhome disable.
We've got nodes, disks and filesystem, ready for deployment. But first, let's save VM snapshots in case we mess up something and need to revert, by running this command on the host: vagrant snapshot save before-installation.
Finally, run ./spectrumscale install. If all goes well, you might go for lunch at this point as the whole process will take at least 30 minutes. More likely, it will fail at some point. IBM Storage Scale Installation Toolkit runs some pre-checks and creates a temporary repo during installation, unfortunately it needs to repeat it during every attempt and it takes (on my slow inadequate hardware) about 10 minutes. Very annoying. Further tasks are more Ansible-style: if something fails, fix the problem and run the installer again, tasks already done will be checked and skipped, failed tasks will be attempted again.